
Joint compilation: Gao Fei, Blake

Lei Fengwang Note: Piotr Dollar became a FAIR research scientist in 2014. His main research areas are computer vision and machine learning. He spent three years at MSR and established Anchovi Labs (acquired by Dropbox in 2012). He received a postdoctoral degree in Computer Vision Laboratory from Caltech in 2011 and a Ph.D. from UCSD in 2007. The latest papers published in computer vision and machine learning include: Learning to Refine Object Segments (2016), A MultiPath Network for Object Detection (2016), Unsupervised Learning of Edges (2016), Metric Learning with Adaptive Density Discrimination (2016) Wait. This article focuses on the computer image segmentation technology and its application, and briefly summarizes the main contents of the three papers that are closely related to this article.
Can a computer recognize as easily as the human eye the many objects contained in a photograph?
Faced with an image, people can easily identify the objects in the image and even recognize the height of the object's pixels in the image. In the FAIR process, we are pushing research in the field of machine vision to a new stage of development. Our goal is to enable machines to understand images and objects at the pixel level as humans do.
In the past few years, advances in the field of deep convolutional neural network research and the emergence of more powerful computing architectures have brought breakthrough improvements and improvements to the precision and performance of machine vision systems. We have witnessed tremendous advancements in image classification (content in images) and object detection (position of objects) (see a and b in the image below). However, the development of these two technologies is only a small beginning to understand the most relevant visual content in any image or video. Recently, we are developing and designing technologies that can identify and segment each object in an image. See the c image on the right side of the image below. This technology embodies a key performance of the machine vision system and will bring new applications. .
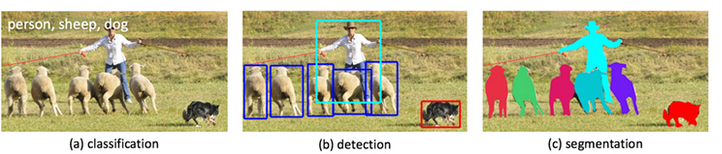
The main new algorithm that promotes our progress in image segmentation is the Deepmask segmentation framework used with our Sharpmask segmentation and fine-tuning module. The combination of two image segmentation technologies allows FAIR's machine vision system to detect and accurately describe each object in an image. In the final stages of the development of image recognition technology, we use a specialized convolutional network called MultiPathNet (multipath network) designed to mark each object according to the category to which the object belongs (eg, humans, dogs, sheep). Mask. Later, we will specifically introduce the specific application of this specialized convolutional network.
Currently, we are coding for DeepMask+SharpMask and MultiPathNet. Our research papers and research-related samples are open to the general public. We hope that our efforts will accelerate research and development in the field of machine vision. We will continue to improve these core technologies. At the same time, we will continue to publish the latest research results and update open source tools that are open to the research field.
Finding patterns in pixels
Let's take a look at how to model these algorithms.
Glance roughly at the first picture below, the one on the left, what do you see? A photographer is operating his vintage camera. A piece of green grass. Picture of buildings in the background. You may also notice other innumerable details. However, a machine may not see these people and objects in the picture you describe. An image is encoded into an array that represents the color value of each pixel, such as the second picture and the right one. So how do we make machine vision understand an image in depth, not just on the pixel level?

This is not an easy task, because in the physical context, objects and scenes tend to change infinitely, and the shape, appearance, size, position, texture, and color of the object change all the time. Considering the above-mentioned changing factors and the inherent complexity of the physical scene, the changing background, the light conditions, and the colorfulness of the world, it is not difficult to understand how difficult it is for the machine to understand each image as deeply as humans.
Let's take a look at deep convolutional neural networks. The deep network architecture is relatively simple, containing tens of millions of parameters that are trained rather than designed, rather than trying to program-defined rule-based systems for object detection technology. These deep convolutional neural networks can automatically learn models from hundreds of millions of marked examples. When looking at a sufficient number of similar examples, such networks begin to apply learned patterns to new images. Depth networks are specifically trained to be able to answer simple yes/no questions about images (classifications). For example, is there a sheep in an image?
Segmented objects
How should we apply the deep network to object detection and image segmentation? The technique we use in DeepMask is to treat segmentation as a large number of dichotomy classification problems. First, for each (overlap) part of an image, we ask: "Is there an object in this part"? Second, if the answer to the first question is “yes†for a specific part, then we ask each pixel of that part: “Is this pixel a component of the central object within that part?†We use an in-depth network to answer this kind of simple question-and-answer question. By making our network more intelligent and making the calculation method applicable to every part and every pixel, we can quickly discover and segment all of an image. Object.
DeepMask uses a very traditional feedforward deep network design method. In such networks, as the network level deepens, information will become more and more abstract and the semantic information it contains will become more and more abundant. For example, the initial layer of a deep network may capture edges and blobs, while the advanced layer will capture more semantic concepts, such as the animal's face or limbs. During the design process, the features captured by these high-level layers will be calculated under relatively low spatial resolution conditions (due to computational reasons and to ensure that these features do not change with small changes in the positions of some pixels). This presents the problem of mask prediction: Advanced layer features can be used to predict masks that are used to capture the basic shape of an object, but cannot accurately capture the edge information of the object.
Why do we use the SharpMask module? SharpMask fine-tunes the output of DeepMask to generate a high-fidelity mask that can more accurately depict the edge information of the object. DeepMask roughly predicts the object mask in the feedforward channel of the network, SharpMask reverses the information in the deep network, and fine-tunes DeepMask's information obtained by using the features predicted by the initial layer in the network. We can look at this process in the following way: In order to capture the basic shape of an object, we need to have a high level understanding of the observed object (DeepMask), but in order to accurately capture the edge information of the object, we need to reflect the low level features according to the pixel height (Sharp Mask). . In essence, it is our goal to use information captured by all layers of a network while supervising small, extra information.
Below are some example output messages generated by DeepMask and fine-tuned by SharpMask. In order to maintain the simplicity of the resulting object image, we only show the predicted masks that are consistent with the actual objects in the image (artificial annotations). It should be noted that this system is not yet complete. The objects with red outlines in the image are artificially marked out, and the information missed by DeepMask.

Classify objects
DeepMask can only identify the type of a specific object. Therefore, although the framework can describe a dog and a sheep in detail, it cannot distinguish between the two. In addition, DeepMask's performance is not that good, and the resulting image area mask may not be too interesting. Thus, how should we narrow the set of related masks to identify those that actually exist?
As you might expect, we will use deep neural networks again. Given a mask generated by DeepMask, we train an independent deep network to classify each masked object type (and "any sort of classification" is not a valid answer). We use a basic parameter first proposed by Ross Girshick—the regional convolutional neural network, or abbreviated as RCNN. The RCNN consists of two phases. The first phase is used to pay attention to certain image areas. The second phase uses an in-depth network to identify the objects that are presented. During the development of the RCNN, the first processing phase was extremely original. By using DeepMask in the first phase of RCNN and using the power of the deep network, we have achieved a great improvement in the accuracy of object detection. The ability to split the image.
To further improve the performance of deep neural networks, we also focused on using a specialized network architecture to classify each mask (in the second phase of RCNN). As we mentioned earlier, the objects contained in the photos of the real world are characterized by many scales, many backgrounds, disorganized distribution, and often obstructed features. For such a situation, the standard deep network will have technical problems. In order to solve this problem, we propose an improved network, which is named MultiPathNet . As its name suggests, multi-path networks allow information to be circulated along multiple paths in the network, allowing such networks to utilize circulating information at multiple image scales and in the context of surrounding images.
In short, our object detection system is a three-stage detection process: (1) DeepMask generates the initial object mask, (2) SharpMask fine-tunes these masks, (3) MultiPathNet identifies each mask description Object. The following are some example output results generated by our complete system:

Since a technology that can perform this simple operation has not been produced a few years ago, our object detection system is not perfect, but it is not inferior.
widely used
Visual identification technology has a wide range of potential applications. The development of this existing computer vision technology has made it possible for computers to recognize objects in photographs. For example, it would be easier to search for specific images without adding labels directly to each photograph. Even without considering image subtitles, the blind group can understand the picture information that their friends share because the system can deliver this information to them.
Not long ago, we have validated technologies developed for the blind. The blind population can use this technique to evaluate photographs and describe the contents of photographs. Currently, when visually impaired users encounter images in their stream of information, they can easily browse photos on Facebook by simply listening to the names of people sharing the photos and the word "photos." Our goal is to provide blind users with richer picture information, such as "Photos of sandy beaches, trees and three smiling people." In addition, using the segmentation technology we have developed, we set the goal of providing immersive experiences for blind users. That is, the user clicks anywhere in the image with his/her finger and the system will describe the content of his click, so that the user can “ See photos.
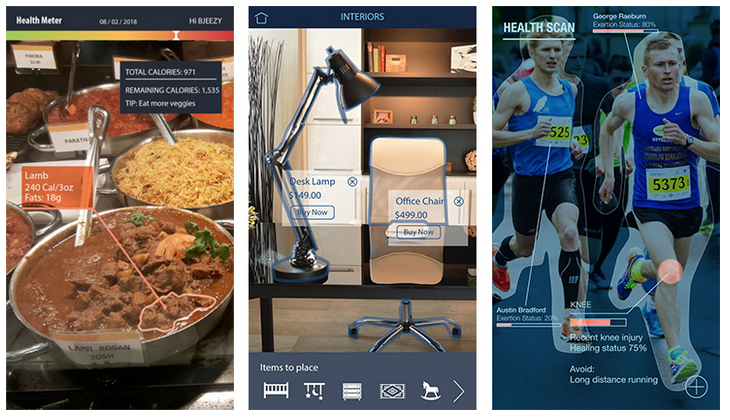
With the advancement of the technologies we have developed, we will continue to improve detection algorithms and segmentation algorithms. You can imagine that one day, image detection, segmentation, and recognition technologies will be used to augment reality, such as in business, healthcare, and other fields.
In addition, the objects in the video are instantly moving and interactively changing. How to apply these technologies to video will become the second challenge we face. We have made some progress in using computer vision technology to watch videos, understand instant content in videos, and classify these contents in three aspects. Real-time categorization technology helps to pick out some relevant and important live video on Facebook, and applies these precise techniques to detect scenes, objects and actions in time and space, and one day it will realize real-time commentary. We are excited to continue to promote the development of this optimal technology and provide Facebook users with a better experience.
The following is a brief summary of the main contents of the three papers that are closely related to the content of this article:

Learning to Segment Object Candidates
Summary
The object detection system has recently relied on two key steps: 1. A series of object detection proposals are predicted as efficiently as possible, 2. The series of candidate proposals is then passed to the object classifier. These methods have proven to be extremely fast while achieving the best detection performance of the moment. In this paper we propose a new way to generate object proposals and introduce a method based on identifying convolutional networks. Our model combines two goals to train together: given an image part, the first part of the output of the system is the partition mask without a category, and the second part of the system output is the part of the entire object that may be the center of the block. In the test, the model is effectively applied to the entire test image and a series of split masks are generated, each of which is assigned a corresponding object similarity score. Tests show that our model achieves better than current performance results in object detection proposal algorithms. In particular, compared to previous approaches, our model achieved better object detection performance using fewer recommendations. In addition, our results also show that our model can deduce unknown categories (unused in training). Unlike all previous object masking methods, we do not rely on edges, superpixels, or any other form of low-level segmentation.

Learning to Refine Object Segments (Learning to Refine Object Segments)
Summary
Object segmentation requires object-level information and low-level pixel data. This poses a challenge for feedforward networks: the lower layers in the convolutional network can capture rich spatial information, and the higher layers in the network encode object-level knowledge, but there are constant factors such as pose and appearance. In this paper we propose to add a feedforward network (with a top-down refinement method) for object segmentation. This bottom-up/top-down architecture can effectively generate high-fidelity object masks. Similar to the jump connection, our method takes advantage of all the features of the network layer. Unlike jump connections, our method does not attempt to output independent predictions at each level. Instead, we first output a preliminary "mask" in the feed forward pass and then improve the mask in the top-down pass (using features in the low-order success level). This method is very simple, rapid and effective. Based on the recent DeepMask network to generate object proposals, we achieved an average of 10-20% accuracy improvement. In addition, by optimizing the overall network architecture, our method SharpMask is 50% faster than the original DeepMask.

A MultiPath Network for Object Detection
Summary
The recent COCO object detection dataset presents several new challenges, in particular it includes a wide range of objects, fewer prototype pictures, and requires more precise positioning. In order to solve these challenges, we tested three modification methods based on the Fast R-CNN object detector: 1. The jump-connected detector gives access to the features in multiple network levels. 2. A central architecture is developed in multi-object processing. Object Text 3. An internal loss function that can improve positioning and corresponding network adjustments. The result of these adjustments is that information can flow along multiple paths in our network, including multiple network-level features and views of multiple objects. We refer to the improved classifier as the "MultiPath" network. We combined the MultiPath network with the DeepMask object suggestion method and combined it with a 66% increase in performance based on the combination of the benchmark Fast R-CNN detector and selective search. (This system was acquired in the COCO2015 detection and segmentation challenge. Second place).
PS : This article was compiled by Lei Feng Network (search "Lei Feng Network" public number attention) , refused to reprint without permission!
Via: Facebook FAIR